2021.11.28 - [Data Engineer] - Big Data World, Part 1: Definitions
Big Data World, Part 1: Definitions
Big Data의 전체 기본적인 개념이 부족하여 자료를 서칭 하는 중에 JetBrains에서 공개한 Big Data World Series의 내용을 정리해 볼까 한다. https://blog.jetbrains.com/blog/2021/05/04/big-data-world-part-1-..
hkim-data.tistory.com
이전 포스팅에 이어 이번 포스팅은 Big Data를 활용하여 일하는 전문가들의 역할에 대해 알아본다.
역시 이번 포스팅도 JetBrains의 포스팅을 정리한 포스팅이다.
https://blog.jetbrains.com/blog/2021/05/13/big-data-world-part-2-roles/
Big Data World, Part 2: Roles | JetBrains News
In this part, we’ll talk about the roles of people working with Big Data. All these roles are data-centric, but they’re very different. Let’s describe them in broad brushstrokes to understand better who are those people we target.
blog.jetbrains.com
Table of contents:
Data Engineers
저자가 설명하기를 데이터 엔지니어의 업무에 대해 파이프라인의 은유를 사용하곤 한다고 하는데, 데이터 엔지니어는 소스부터 타깃까지 데이터 파이프라인을 구축한다고 한다.
빅데이터로 넘어오면서 많은 운영 데이터베이스와 다른 다양한 데이터 소스들은 필수적이고 피할 수도 없다. 이런 데이터들을 결합하고 처리할 수 있어야 한다.
이러한 파이프라인 설계 및 구축 이외에도 Data Warehouse를 구축하는 업무도 있는데, 이는 이전 포스팅에서 설명한 3V scaling 때문에 보기보다 간단하진 않다.
예를 들어 사용자의 프로필을 유지해야 한다고 가정할때, 이 프로필에는 트랜잭션 목록, 집계된 클릭스트림에서 수집된 데이터, 거의 변경되지 않는 안정적인 데이터, 계산된 메트릭, 권장 사항 등 많은 항목이 포함된다.
한 명의 사용자를 위해 저장하는 것은 문제가 되지 않지만 수십만, 수백만 사용자를 위해 보관하는 것은 상당히 어려울 수 있다고 설명한다.
이것뿐만이 아니라 매일 업데이트되거나, 임의의 쿼리 작업을 수행해야 한다고 하면 실제로 매우 복잡하고 문제가 많이 생길 여지가 다분하다.
또한 이는 완전히 분리된 데이터 관리 플랫폼이라 한다.(이는 정확히 무슨 뜻인지 모르겠다)
- 아마 특정 타겟을 클래스 화해서 분리할 수 있어야 한다는 것 같다.
DMP 관련 영상
https://www.youtube.com/watch?v=InWulBTDjL8
데이터 엔지니어들은 일반적으로 소프트웨어 엔지니어, DBA, Ops가 혼합되어 있다.
데이터 엔지니어가 사용하는 Tool
- Batch processing tools (like Apache Spark)
- Stream processing tools (like Apache Kafka and Apache Flink)
- Columnar storages (like parquet or ORC)
- Query engines (like Presto or Apache Hive)
- MPP, massive parallel processing DBs (like Vertica)
- OLTP DBs (like Postgres and Oracle DBs)
- Orchestrators (Luigi, Apache Airflow, etc.)
- Object storages (S3, HDFS, etc.)
- IDEs (like IntelliJ IDEA with the Big Data Tools plugin)
내가 사용해본건 Spark, parquet, Postgres, Airflow, S3 정도가 있다.
개인적으로 HDFS이나 아파치 하둡같은 것을 좀 더 다뤄보고 싶다.
추가적으로 데이터 엔지니어가 사용하는 대표적인 언어는 python과 scala가 있다.
또한 자동화를 추구한다.
Data scientists
데이터 과학자들은 데이터 과학을 적용하는데, 여기서 데이터 과학을 Wikipedia에서 알아보면
데이터 과학은 과학적인 방법, 과정, 알고리즘 그리고 시스템을 사용해서 정형, 비정형 데이터로부터 지식과 통찰력을 찾아내는 학제 간의 분야라고 설명한다.
데이터 과학자들은 데이터를 이해하고 탐험하기 위해 대게 통계적 방법을 활용한다. 많은 양의 데이터를 다루는 것은 큰 문제이다. 인간의 뇌는 그런 많은 데이터를 기억하고 분석할 수 없다.
다차원 데이터 속에는 숨겨져 있는 상관관계나, 패턴들이 존재할 수 있고, 데이터 과학자들은 이를 찾기 위해 노력한다.
데이터로부터 통찰력을 얻는 것 이외에 추가적으로 다음과 같은 두 가지 이유로 실험 분석을 진행한다.
1. 이를 바탕으로 결론을 내릴 정도로 충분한 데이터가 수집 되었는지 알기 위해
2. 실험들 끼리 어떤 영향을 끼쳤는지 이해하기 위한 순수한 수학적 작업
또한 데이터 과학자들은 “Neural Networks”, “AI,” or “ML” 의 책임이 있다. 또한 데이터 엔지니어와 함께 더 쉽게 생산하기 위해 사용 툴을 같이 선택한다.
OpenAI
OpenAI is an AI research and deployment company. Our mission is to ensure that artificial general intelligence benefits all of humanity.
openai.com
위와 같은 거대한 제품들은 모두 능력 있는 데이터 엔지니어와 데이터 과학자들의 작업의 결과물이다.
아래는 데이터 과학자들의 사용하는 대표 툴이다.
- Neural networks (like PyTorch, TensorFlow, etc.)
- Notebook software (like JupyterLab, Google Colab, Apache Zeppelin, Datalore)
- Math libs (like NumPy, PyMC3, etc.)
- Plotting libs (like Matplotlib, Plotly, etc.)
- Feature engineering tools (like MindsDB)
- BI (Business intelligence) tools and frameworks (like Superset, Redash)
내가 사용해본 건 PyTorch, TensorFlow, JupyterLab, Google Colab, NumPy, Matplotlib 정도가 있다.
정말 툴이 많다..
이어서 저자는 데이터 과학자의 특징을 설명하는데, 그들은 많은 연구를 진행한다고 한다.
연구의 특성상 현재의 접근법으로 성공할지 언제 성공할지 알 수 없고, 최대한 빠르게 성과를 내기 위해 지속적인 실험 및 코드를 변경한다고 한다. 그래서 머신러닝 엔지니어가 필요하다고 함.
또한 데이터 과학자들은 연구 뿐만연구뿐만 아니라 이를 활용하여 복잡한 서비스를 개발한다고 함. 실제 개발에서 필요한 것은 과학적 연구뿐만 아니라 엔지니어링 기술과 비즈니스에 대한 이해가 필요하다고 함.
ML engineers
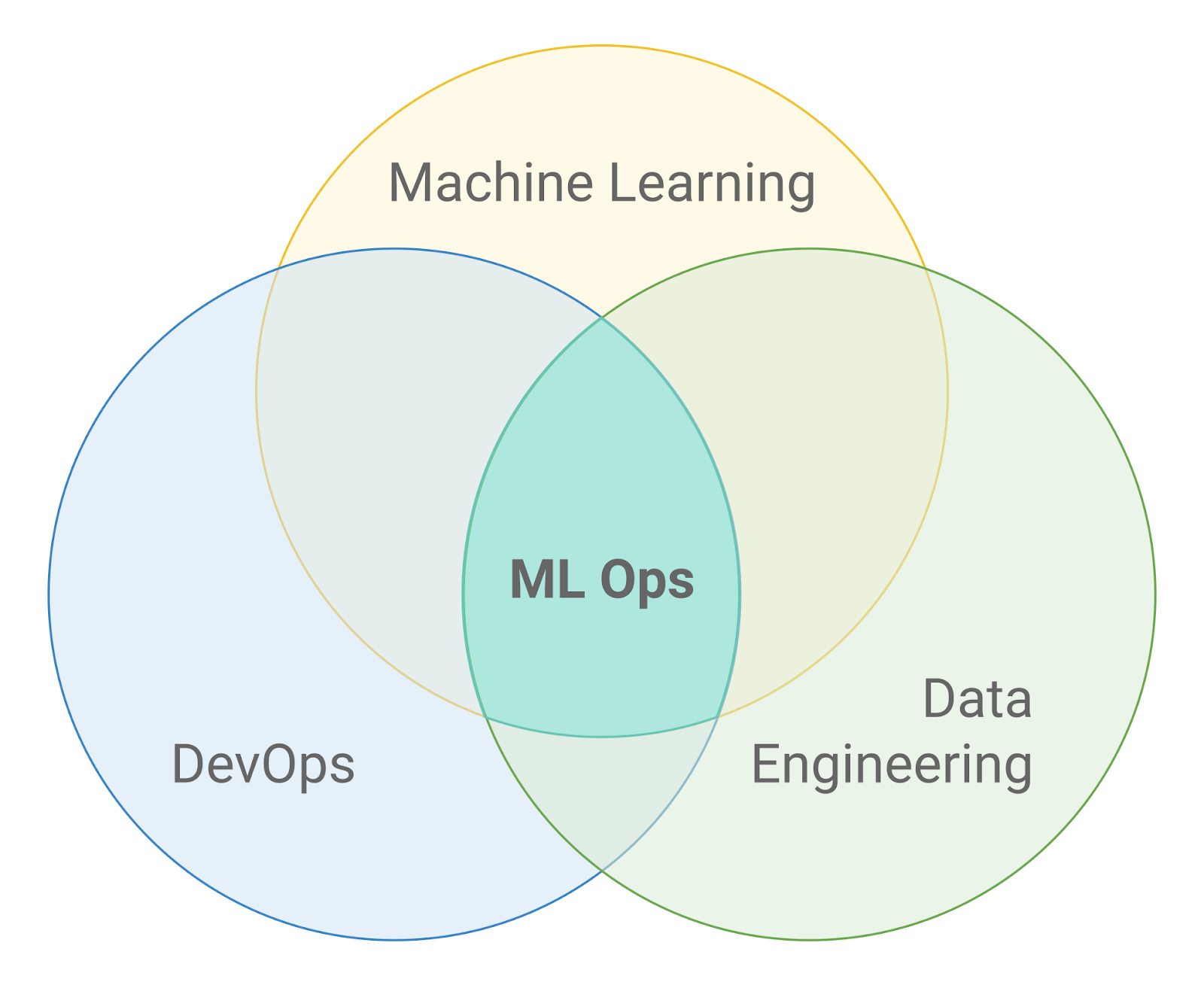
상단 그림은 ML Ops가 존재하는 위치를 보여주는 그림이다.
ML 엔지니어는 단순히 코들르 작성하는 것 이외에도 많은 할 일이 있다고 설명하고
MLOps: 머신러닝의 지속적 배포 및 자동화 파이프라인 | Google Cloud
MLOps: 머신러닝의 지속적 배포 및 자동화 파이프라인 이 문서에서는 머신러닝(ML) 시스템을 위한 지속적 통합(CI), 지속적 배포(CD), 지속적 학습(CT)을 구현하고 자동화하는 기술을 설명합니다. 데
cloud.google.com
상단 구글 포스트에서 ML ops의 필요성에 대해 잘 설명한다.
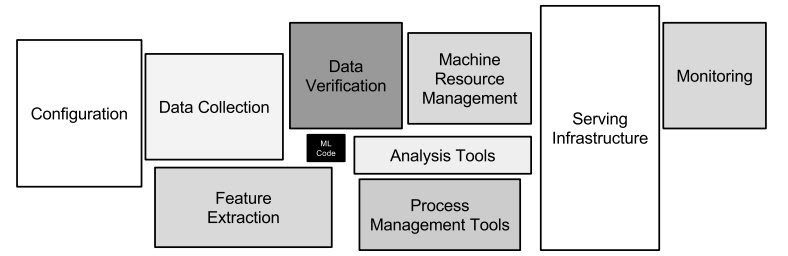
머신러닝 시스템을 만들기 위해 많은 작업이 필요하다.
코드를 배포하고, 신뢰성 있게 작동하고, 사용 가능해야 함. 또한 사전에 데이터를 수집하고, 정제해야 함.
- 아무튼 할일이 정말 많다..
머신러닝 엔지니어의 주요 사용 툴이다.
- Data versioning tools (like DVC)
- Model serving software (like MLflow)
- Deployment tools (like Kubeflow)
- Monitoring tools (like MLWatcher)
- Privacy-preserving tools (like PySyft)
지금까지 데이터 업계에서의 다양한 업무에 대해 알아봤는데, 사실 이는 역할을 어느 정도 나눴을 뿐 회사마다 맡는 업무가 합쳐지는 경우도 있고, 더 세분화해서 나눠지는 경우도 있다고 한다.
Useful links:
- Awesome Data Engineering learning path
- Awesome production machine learning list
- Continuous delivery for machine learning
- MLOps: Continuous delivery and automation pipelines in machine learning
- JetBrains Tools for Data Science & Big Data
- Big Data Tools plugin
앞으로 하단 Learning Path를 공부하는 방식으로 계획을 짜야겠다는 생각이 들었다.
Awesome Data Engineering learning path
Awesome Data Engineering - Best resources, books, courses for learning
Awesome Data Engineering Learning path and resources to become a data engineer Best books, best courses and best articles on each subject. How to read it: First, not every subject is required to master. Look for the "essentiality" measure. Then, each resou
awesomedataengineering.com
'Data Engineer' 카테고리의 다른 글
| 데이터 직렬화 Serialization (0) | 2022.03.22 |
|---|---|
| Big Data World, Part 3: Building Data Pipelines (0) | 2021.11.28 |
| Big Data World, Part 1: Definitions (0) | 2021.11.28 |


댓글